You're Overcomplicating Everything
26 March, 2025
Modernization Is My Least Favorite Buzzword
Reminds me of Microservices.
At my first real job in tech as tech support and sysadmin I had to manage a handful of servers that were important to the company; Active Directory Domain Controllers, File Servers, Print Servers, etc. I used simple remote management tools (RDP) to manage them. I backed them up, I care and fed for them like they were my pets. There were maybe 15 servers and 30 network devices.
I later started working at a hosting company that had hundreds of clients and servers to manage; they were mostly LAMP stacks, virtual machines running things like Apache, Nginx, MySQL, php-fpm, Puma, Gunicorn, IIS, Apache Tomcat, etc. I did a lot of work SSH'ing into machines to read logs and troubleshoot and eventually had to take a more automated approach using tools like Ansible and later Chef. They were still cared for like pets, not completely ephemeral, but we managed just fine. Customers ran deployments with tools like Jenkins which would publish code changes by updating the filesystem or copying over new binaries and reloading services.
When we started running clients on AWS we stuck to the basics; LAMP stacks on EC2 (most of our customers were running simple sites). As our clientele became more sophisticated, we had to build for scale; autoscaling EC2, RDS, S3, Elasticache, etc. Software releases had to become more streamlined in an autoscaling group which forced different deployment methods, each with their own caveats:
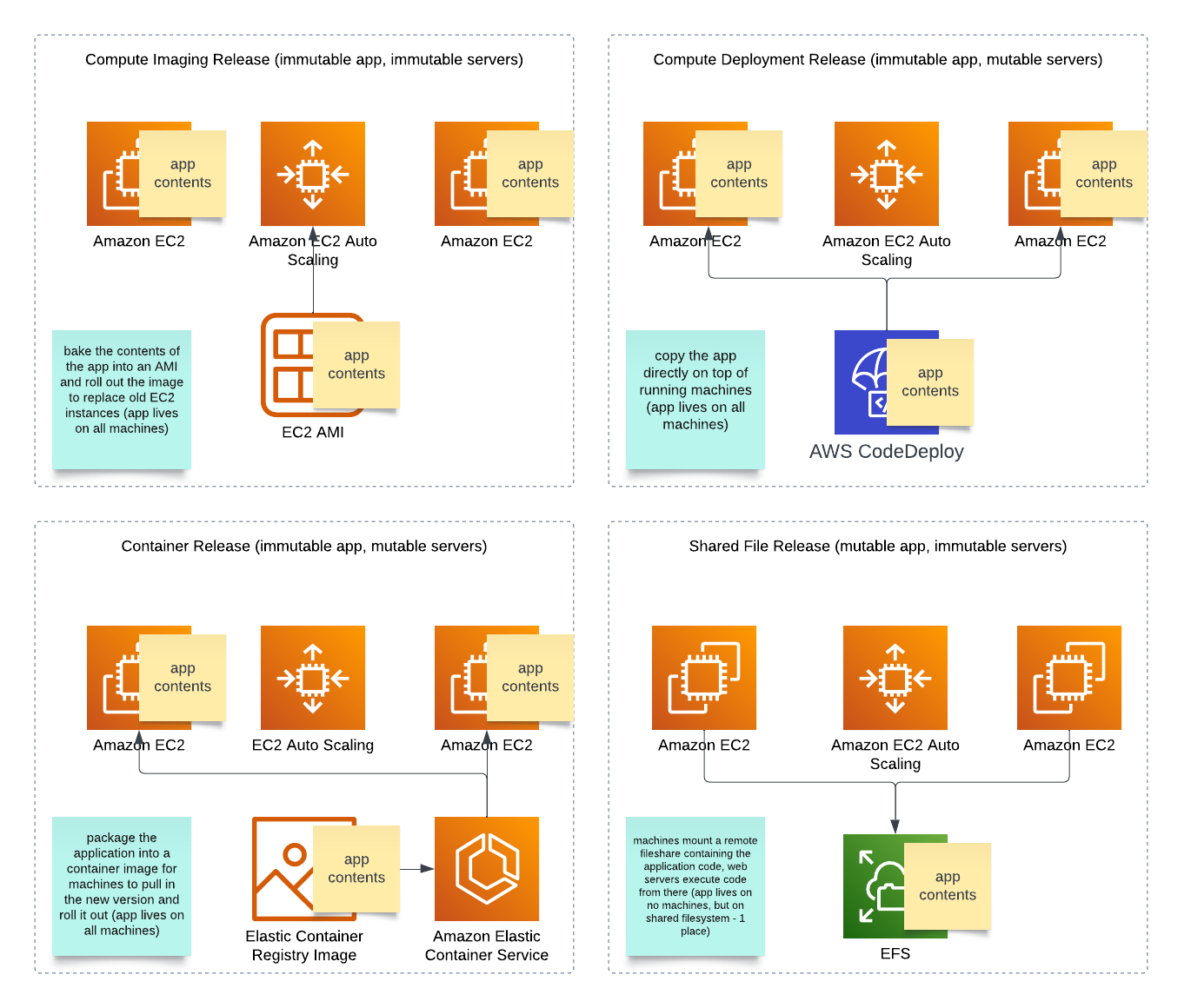
We could work it out with the customer which way made the most sense for them because they all have pros and cons. We also started using infrastructure-as-code tools so we could manage the infrastructure in a more programmatic way as well, starting with Cloudformation, then Terraform. We used the web console for troubleshooting and had CI/CD pipelines for infra + software releases.
Most of the "automation" was actually simple shell scripts run on a cron timer or in some CI service.
The CNCF Era
In 2016-2017 I remember being enamored with the Google SRE handbook. It resonated with me and I felt strongly that a similar approach would be beneficial in my environment. I started hearing about tools like Kubernetes and the CNCF; ever since it's been a total cultural phenomenon. These days half of the customers I work with are either running workloads on Kubernetes or have a desire to use Kubernetes and other CNCF tools.
The complexity of environments I see on a regular basis has exploded. We went from needing a few tools to build and run production cloud systems and now "common practices" have become running dozens of different toolkits. Organizations seem to want to model their internal practices to mimic Big Tech Companies and now I constantly hear things from customers like:
- "we want to run kubernetes so we can scale"
- "we dont want to be locked into a cloud platform"
- "we need GitOps workflows"
Yet, with all of this tooling, systems are as complicated and brittle as ever. Customers spend more and more time dealing with the quirks of their toolchains and the complicated machinations they've paper mâchéd over their technology infrastructure. They're breaking apart monoliths so services can scale indepently but fractured their system and introduced new and exciting ways to break things.
They were worried about vendor lock-in but now are being held hostage by open source maintainers with software running in production, tools they are now dependent on. When Kubernetes releases come out they have to ensure consistency between all of these tools because stuff will break on upgrades.
We're stuck on k8s version X until we upgrade our ingress controller, but we can't do that until we refactor our Helm charts to also update our RBAC operator. We also need to update our custom gRPC service because the new version of Y operator has a different payload than our implementation of Protobuf is expecting.
WTF? What should be simple is now convoluted with all of the interdependencies we've introduced ourselves.
Kubernetes was made in the image of a Google platform, Borg, which abstracted thousands of servers in their private data centers around the world into a massive container orchestration system to run Google's technology operations.
The organizations I meet with are using hyperscalers like AWS which abstract thousands of servers in private data centers around the world with APIs and services to run workloads in a number of ways, but many orgs want to run Kubernetes on top of it anyways. We put abstractions on our abstractions in the post-modern world.

Why???
Who knows. I asked Grok for his take on it.
WTF Does "Modernization" Even Mean?!
Please stop saying "modernize".
I hear this all the time. "We want to modernize". Nobody "wants to modernize" for no reason, something is wrong, there is a challenge they're dealing with. So what is actually wrong? I find that the underlying reason is something that is addressable without needing to run a whole new toolkit.
- We can't scale: what does that mean? when you get flooded with traffic your system goes offline? you're constantly dealing with outages? your system costs too much to run and it's eating into profit margins?
- We move too slowly: what does that mean? you are doing manual deployments and it takes too long to deploy? you're waiting on unit tests and your developer feedback loop is too slow? you keep introducing bugs into your platform?
- ???: what does that mean?!?! describe to me what your issues are without saying the word "modern".
People have come to interpret these common issues with needing new infrastructure and tools: we want to run in Kubernetes so it's scalable, we want to rewrite our platform in Golang so we have type safety and less bugs, we want GitOps tooling so we have more release automation, etc.
+90% of organizations don't actually need these things. The uncomfortable truth is actually that their software probably just sucks.
Your Software Sucks
Why everything is just the worst - SadServer
Infrastructure is simply a vessel to house and run software. When orgs are running into challenges they look for shiny tools to solve them, but the reality is that it almost always comes down to how software has been architected, the design patterns in use. Here are some simple examples:
We are constantly dealing with poor performance on our platform. When too many people are using our platform the backend services can't serve all the requests in-time and requests start failing.
You could scale up your backend services (increase the underlying resources) to temporarily address the issues, but the fix is to design your software differently. You could incorporate caching to reduce the strain of your database, you could redesign your data model to introduce new storage and database engines to house your data in different ways, you can optimize your queries and data retrieval patterns, etc. You have to look at the underlying reasons for why you're experiencing issues and adopt new architecture patterns with software designed for your use case to address them.
We are constantly dealing with outages on our platform and struggling to make improvements, just constantly firefighting. We don't have great visibility into why things break.
You can't always just inject a tool into the mix to get insights. DataDog and New Relic are great, but you don't need these tools for insights and observability. You have to incorporate robust logging into your software, it has to emit events and metrics that are relevant for operators, and they have to be collected and aggregated. Tools like Prometheus are great at part of this but you still have to modify your software to expose health and metrics endpoints.
We have a lot of manual deployment steps that bog our team down and cause us to move slowly.
You can just script these steps. It doesn't need to be fancy. Shell scripts and Makefiles will outlast all of us. If you cannot automate process...why? It sounds like your software should be improved so that testing and deployment is automated. You should also be able to segment your tests so you can test only the parts you need to instead of an entire testing library on every change. You don't need fancy tools for this.
+90% of the time when I'm working with people the answer to their challenges is actually just to make their software better, but nobody wants to have that conversation, they just want a seemingly quick fix.
You Can't Optimize For Scale
At some point, no amount of refactoring and optimizing will save you from legitimate traffic and load. You will eventually need more infrastructure (larger vessels) to run your system, but that doesn't necessarily mean new tools, just scaled up or scaled out systems. You want your software to be lean and mean, generating more revenue for the business than what it costs to run.
You have to know when to strike that balance.
Keep It Simple
Here's an example of what I mean. Compare the following architectures of a common application stack deployed on AWS. One is "simple" the other is "modern". Compare and contrast.
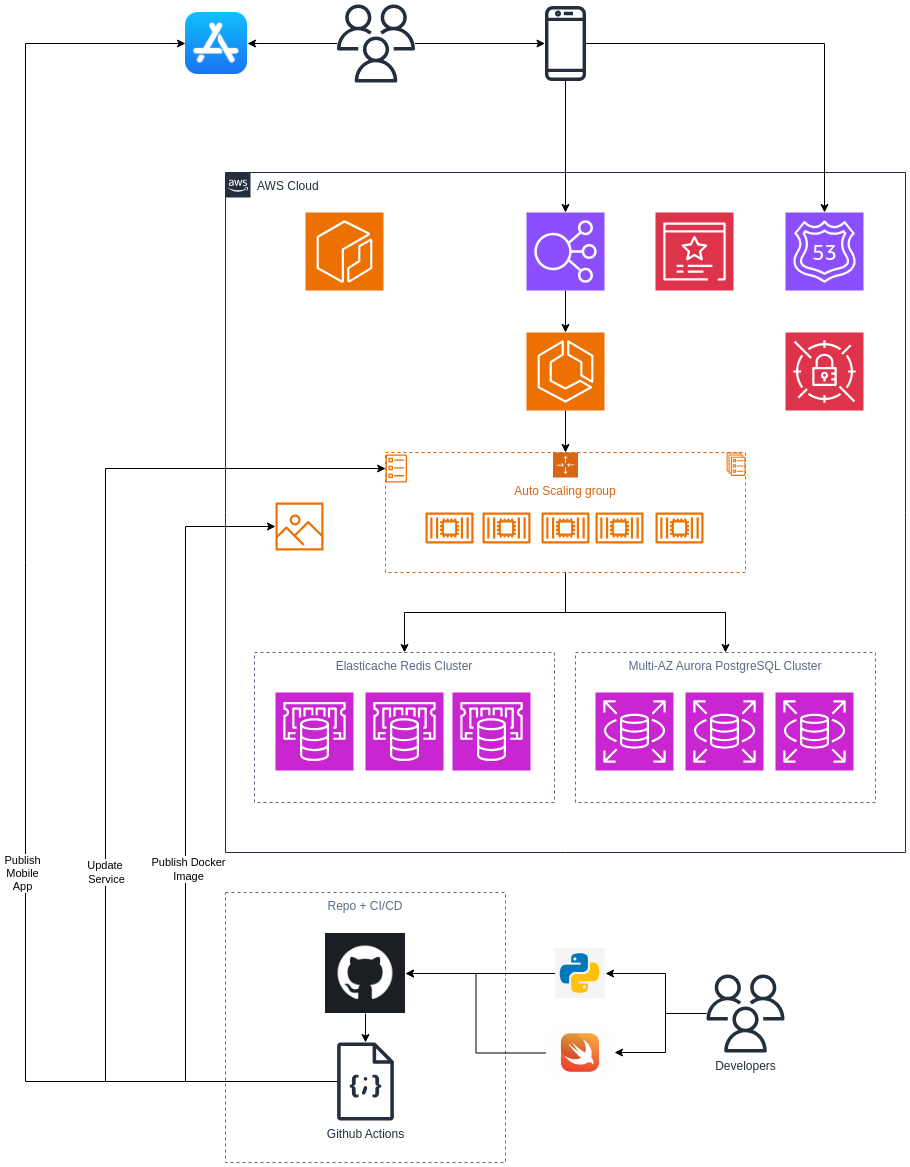
Simple ECS Deployment
This is how I would deploy a new mobile backend on AWS. I'd package up the API software as a container image and run it on ECS with autoscaling EC2 (because they can cache images, less spin up time compared to Fargate). I'd use AWS services for the relational database and cache, RDS PostgreSQL and Elasticache Redis. I'd also use AWS services for DNS resolution (Route 53), load balancing (Elastic Load Balancing), TLS certificate management (Certificate Manager), and secrets management (Secrets Manager).
I would use Terraform or Cloudformation to provision and manage the cloud infra and shell scripts in CI pipelines to build, publish, and deploy the container image using Docker + AWS CLI commands.
To troubleshoot issues we'd view logs and metrics in Cloudwatch via console or API. The API software will emit logs and metrics which we can use for dashboarding and alerting.
This architecture will run without the need for much manual intervention. There's no upgrading cluster versions or core software, just deploying new versions of the application and tweaking infrastructure bits if new functionality is needed (some state tables in DynamoDB or CDN w/ Cloudfront for example). This will be as solid as a rock, running smoothly unless you push buggy code or receive a huge burst of traffic.
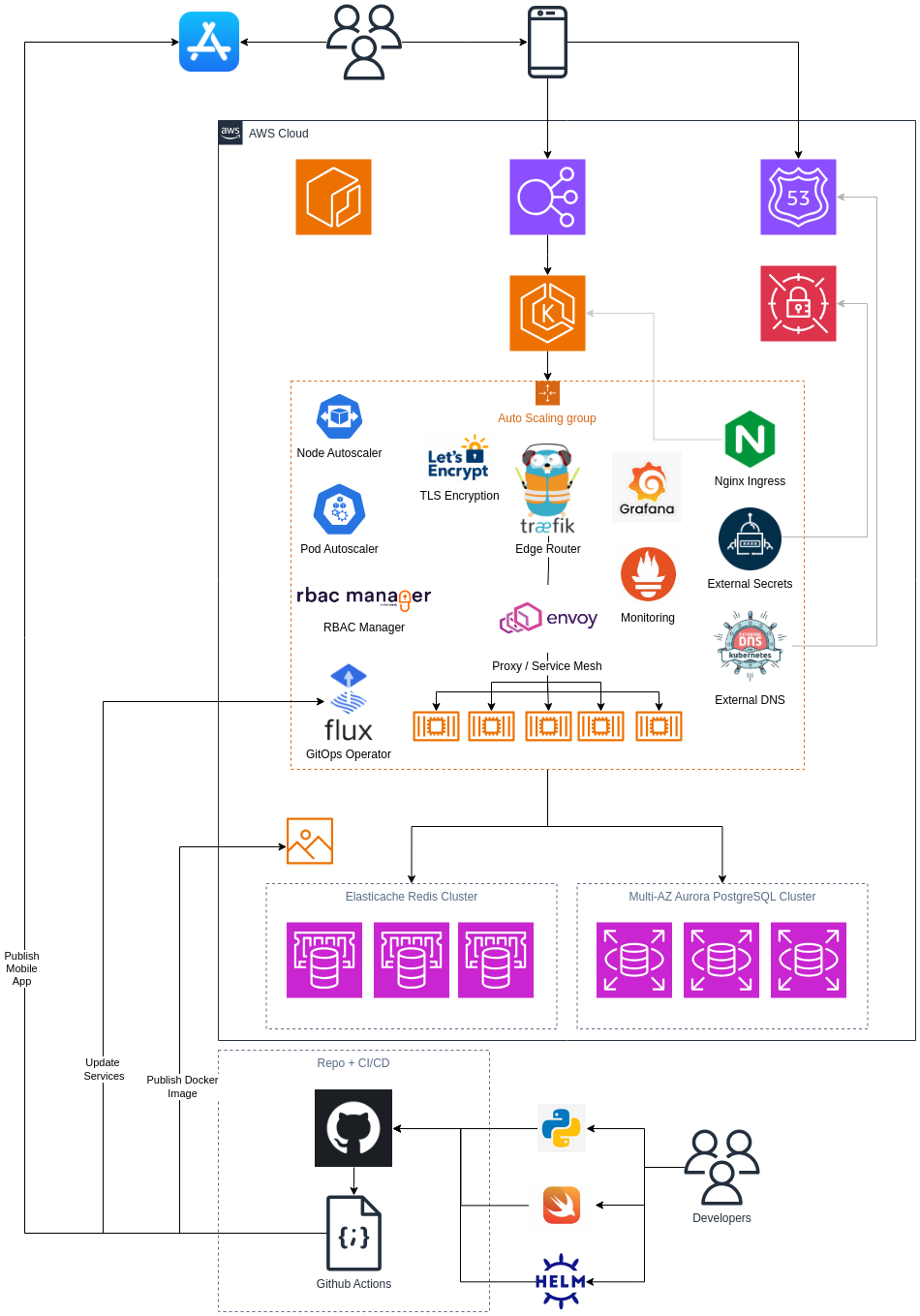
Modern Kubernetes Deployment
This is the same mobile backend but deployed on EKS instead. The software would also be packaged as a container image and deployed to a cluster. We'd still use Route 53 for DNS, Elastic Load Balancing, and Secrets Manager. We'd also still deploy the cloud infra with Terraform or Cloudformation. However, this one requires some extra steps.
We'd now have a running k8s cluster which we'd need to deploy resources into. We'll use Helm to express our k8s deployments and services. We also need some in-cluster add-ons for advanced, modern automation capabilities:
- Nginx Ingress Controller for automatically provisioning load balancers
- External Secrets for allowing the cluster to interact with secrets in Secrets Manager natively within k8s
- Traefik for edge routing (with built-in Let's Encrypt ACME certs + TLS encryption)
- Cluster Autoscaler for scaling out k8s worker nodes in an autoscaling group
- Horizontal Pod Autoscaler for scaling out pods of our services
- RBAC Manager for maintaining RBAC policies for cluster users/accounts
- Flux for automatically updating the cluster based upon Helm charts in Git repo
- External DNS Controller for automatically updating DNS records for services
- Envoy Proxy for an internal service mesh for encrypted inter-service communications
- Prometheus for polling services and capturing metrics
- Grafana for operational health dashboards and monitoring
Each of these additional controllers, operators, and services are a bespoke piece of software with their own git repositories and installation and upgrade procedures (though most, if not all, have Helm charts you can deploy or copy). They each will have their own versioning cadence and will each need to be checked for compatibility with Kubernetes versions as you make upgrades to your core cluster.
Some of the tools don't even add new functionality, they're only there to operate the cluster more efficiently like it would be on a vanilla ECS deployment (RBAC manager, autoscalers, etc), yet come with their own management overhead.
They also have their own logs and metrics so you'll need to monitor them closely, because if something breaks it will likely affect your production environment.
Do You See What I'm Saying?
Both of these systems accomplish the same things. There's full-stack automation and a complete cloud deployment. However, one takes way more work to setup, requires way more attention to maintain, and has a much larger risk surface meaning way more things can break and go wrong. Sure, it can also infinitely handle anything you may need to do in the future, but at the cost of all this pain now. It's premature optimization for +90% of orgs.
...But These Are Simple Examples
Sure, but you would be surprised how often this comes up, even for a system as simple as this.
If you disagree with my central thesis but agree that this example doesn't warrant a k8s deployment, try this exercise. Slowly ramp up the complexity of this workload. Add new features, new services... 20 services, 50, 100+.
At what point of scale does the threshold tip over and it makes sense to run k8s?
To me, it starts making more sense for enterprises with dozens if not hundreds of software engineers and a dedicated team of sysops/devops engineers. Whenever I see startups and SMB teams using k8s I can't help but feel like they're making things harder on themselves.
I think I've said "Kubernetes makes sense for you" like 10 times and I've met hundreds of prospects and customers.
One of those was a customer who hosted websites and integration services for their users. They allowed their customers to point their own managed DNS records at their load balancers + IPs and they needed hundreds of TLS certs provisioned and managed on their edge routers. Traefik made sense for them, k8s did make sense. Granted, it's still not vital, you can use Traefik without it, but I still felt it was warranted.
Good Use Cases I've Seen
I generally look for the following benchmarks when determining if it's truly the right fit for a customer:
- Stringent security requirements. Services must communicate and authenticate via mTLS.
- Large amount of TLS certificates needed across several distinct domains. ACM + ALB falls short of this, there are limits on how many certs can be attached to load balancers. Something like Traefik Edge Routing with Let's Encrypt works well.
- Same as above but with automated DNS records. External DNS controller provides an easy way to bulk manage DNS by applying labels to k8s resources.
- Very large teams who would be tripping over each other without the guardrails that k8s can provide.
- Hybrid cloud deployments. It's better when operations runs the same regardless of the cloud platform otherwise you would end up with tool sprawl.
I Digress
I'm not complaining, just venting about the direction I've seen in the market, and in fact, this all gives me good job security (for now). However, it's also my job to advise my customers of the right path to address their issues and I would be doing them a disservice by not giving them a simpler path.
This wasn't intended as a dig at Kubernetes or the CNCF ecosystem, I do think it's a good toolkit for some orgs, but they're usually on the upper bounds of the complexity scale. It's just an easy example to point to on the topic of overengineering saturating the market.
I've been working in the AWS consulting and engineering space for the past 10 years and worked with customers in every industry and segment (startup, SMB, enterprise). I have a good birds eye view of the landscape. In the spirit of being a helpful cloud consultant and architect, I will leave you with my advice and how I address issues with customers:
- What are your most pressing challenges with your technology infrastructure? Describe them in as much detail as possible.
- What is the underlying reason for the issue?
- Can your software be modified to address the issue?
Don't select a tool and assume it solves your issues, figure out what the root cause of the issue is, and then figure out a game plan to address it. Start on the simple end of the spectrum, work your way out, iterate on it, game theory it. Anything you do will result in another set of issues, the game is about balancing the issues you're comfortable keeping around while resolving the main problems.
The cloud is supposed to make things simpler and easier, more elastic, more compelling. I've seen sentiment slowly shifting away from that and into "too expensive, too complicated". Some orgs are even leaving the cloud altogether. I standby the fact that anyone can effectively scale their business on AWS but there are a lot more ways to do it incorrectly than there are to do it correctly.
I just started a new position at VeUp as a Solutions Architect. We're an AWS consulting and engineering shop. I think we're going to build some great things with the team we're assembling.
Contact links available on the home page if you want to chat about it or tell me I'm a moron :)