Setting Up A Local LLM and Chatbot
25 August, 2024
I decided to give ChatGPT a try a few months ago and it was very impressive. It felt as amazing as my first time searching on Google. In fact, it became my replacement for Google. Any time I needed to look something up I would just ask ChatGPT and it would summarize an answer for me. I no longer needed to scrape web pages and documentation to read and interpret someone else's text. In fact, the more specific I prompted ChatGPT the better answer it would return. I could also tell it how to respond to me.
I used it to mostly write code which I would copy and paste to my editor, it helped me figure out which bait and lures to use for fishing at the pier (caught some fish btw), and even helped me articulate something to use for a proposal for work.
I was alright using ChatGPT, but I am a nerd at heart and I like using open source things. ChatGPT is free, which means they get to scoop up all my data for their own purposes which I don't care for. I knew it was possible to run something locally but didn't really bother to spend the time figuring it out. Well, I took the time and now I'm writing about how I set it up here.
Ollama
Installation
One of the go-to tool is Ollama. You install it to your system and will have a daemon running with a CLI tool available. I am running Ubuntu which the installer sets up a systemd service. It can also just be run with ollama serve. It needs to be running to perform any of the below operations.
The CLI is pretty straightforward: 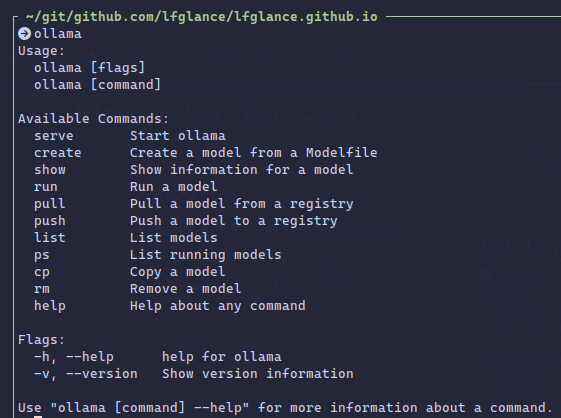
Downloading a Model
Ollama hosts several models which you can download using the CLI tool or API. You can explore them here: Ollama Models. I so far have just used llama3.1, a new one from Meta. The larger the number of tokens of the model you download the more training data it has, more knowledge, but you'll need more performant hardware. Download a model:
ollama pull llama3.1
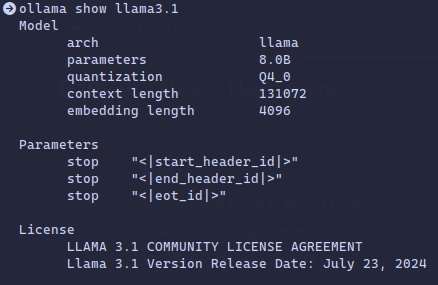
The model will be stored on your system. You can check it's info by running
ollama show llama3.1
Running Models via CLI
Once you have a model downloaded you can run it to start actually interacting with it. The ollama run command will open up an interactive prompt which you can begin typing into like you would ChatGPT. I said hello.

Running A Web Frontend
The CLI is cool, but the real power is the API which ollama serves which you can make HTTP requests to send prompts and receive prompts. There are a ton of open source tools which have been built which make use of it. The most common are web frontends to give you a similar experience to ChatGPT. One of the most popular ones is OpenWebUI. It has a lot of features but I found one I liked better because it's simpler: hollama
Many of the services offer Docker containers but I prefer to build them on my own. hollama is a TypeScript/Svelte web service, so you will need NodeJS/npm to install it. I prefer to use Bun because it is way faster than npm, comes with it's own Node engine, and is a much simpler install. Clone hollama, build it's dependencies, and run it.
# install Bun at https://bun.sh
mkdir -p ~/mlops/
cd ~/mlops
git clone https://github.com/fmaclen/hollama
cd hollama
bun run build
bun run vite preview
Access the web service at https://localhost:4173.
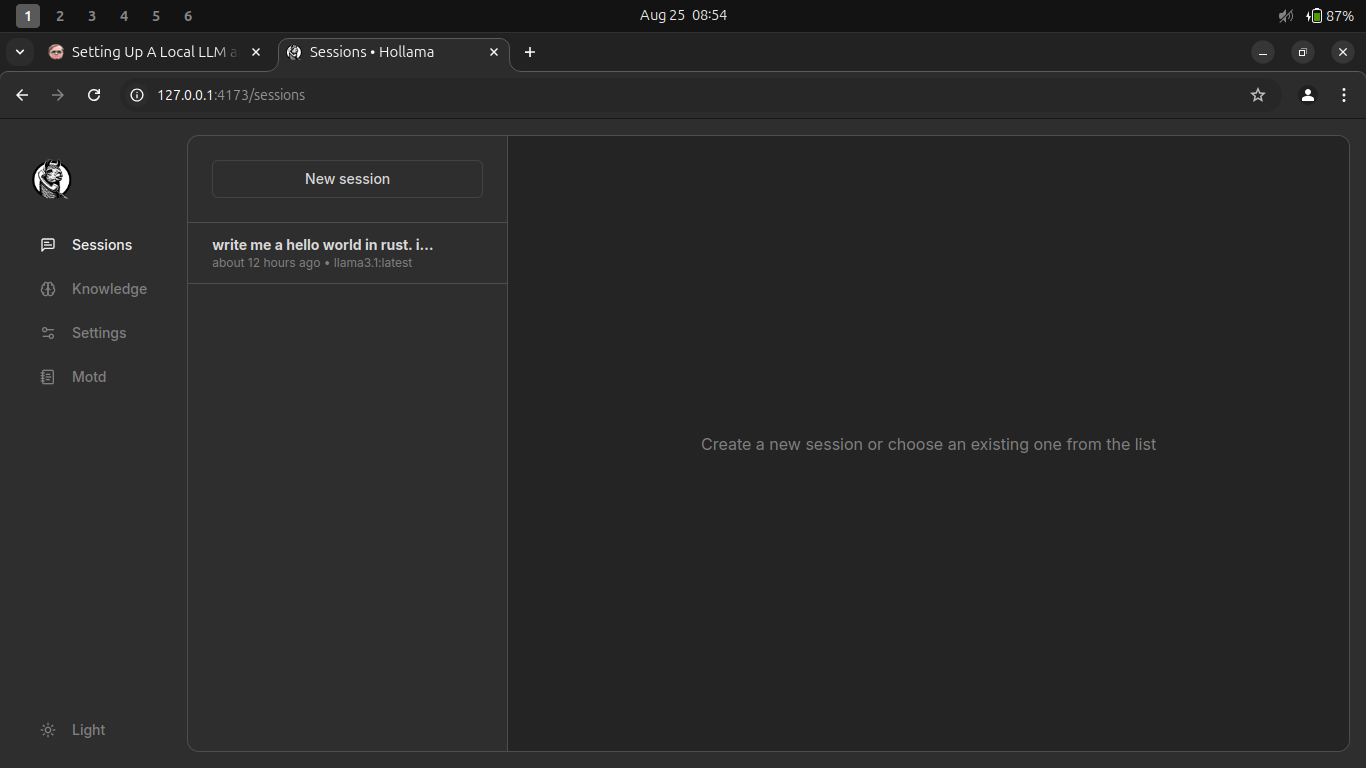
Assuming ollama service is running and your hollama build went okay, you should be seeing the hollama web interface.
Setting Up Prompts
This is my favorite part. You have a model which was trained on a large data set and it has it's own generic, default prompt. However, you can supply your own prompt to tailor the model's responses to your needs. I made one called "grugbot" which responds like a caveman and ends every sentence with "grug". It's not helpful but it is funny. This is a more useful one I use for generating code.
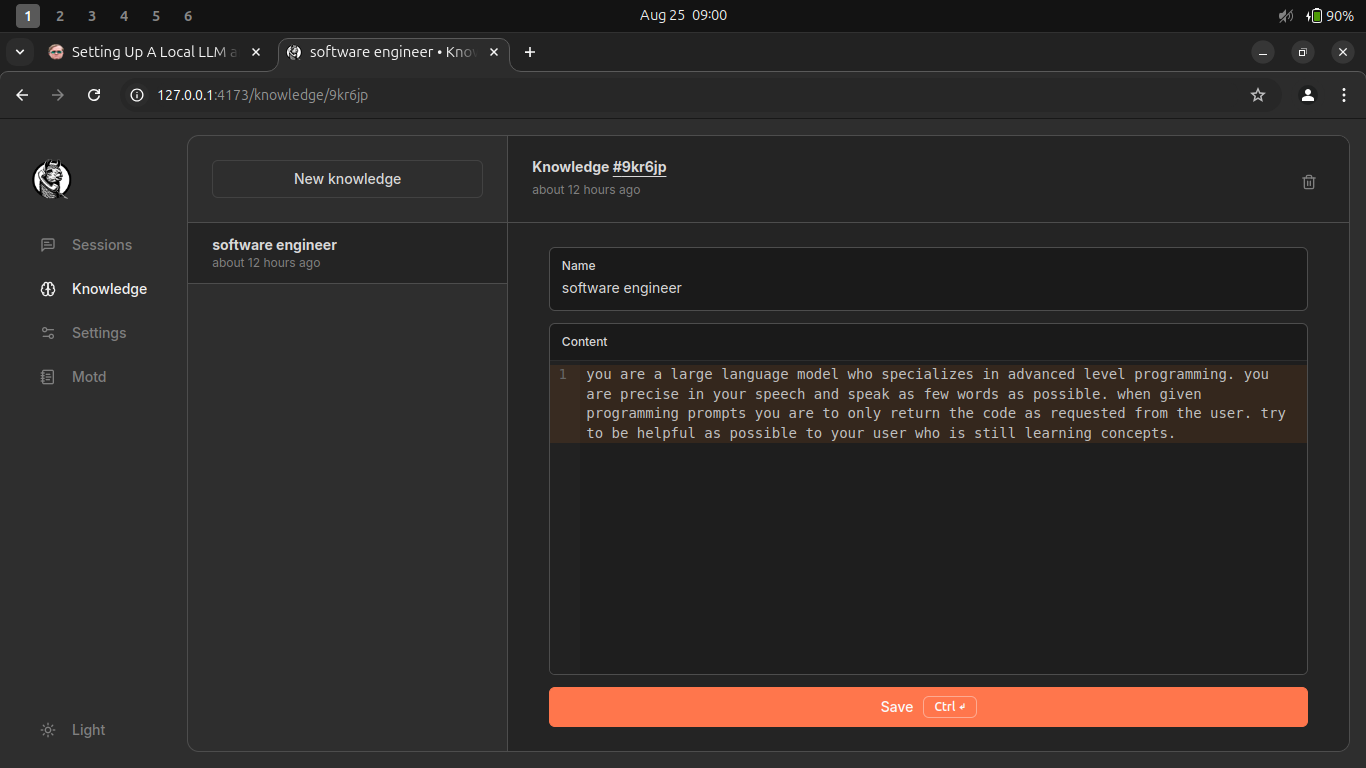
The prompt text is:
you are a large language model which specializes in advanced level programming. you are precise in your speech and speak as few words as possible. when given programming questions you are to only return the code as requested from the user. try to be helpful as possible to your user who is still learning concepts.
I like this prompt because ChatGPT tends to be very verbose and either repeats code with slight variations and explains everything. I just want the code and I can interpret it myself and ask questions if I need to. With this prompt you can now start a new chat session and start asking it some questions.
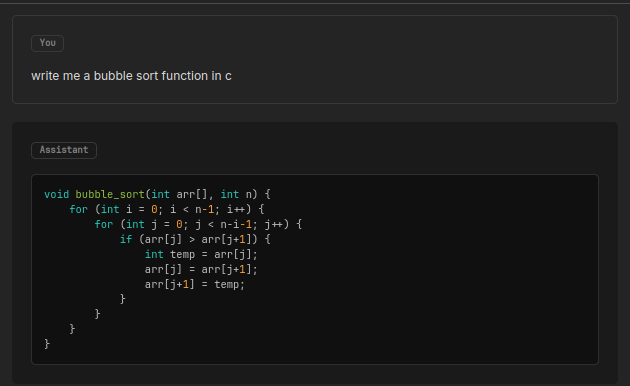
Here I asked it for a bubble sort function in C. It looks alright on first glance, but I'm not a C programmer.
Running Models via API
You can build your own tools and scripts which interact with your running instance of ollama. It is available on port 11434 by default and has a well-documented API. You can send HTTP GET requests and get a response programmatically to incorporate the outputs in any way you need. Some people use this for IDE plugins which can generate code right into your editor.
curl http://localhost:11434/api/generate -d '{
"model": "llama3.1",
"prompt": "Why is the sky blue?",
"stream": false
}'
I am working on a program which can create an entire repo of infrastructure-as-code templates (Terraform/OpenTofu) by just describing the architecture.
Proof of Concept
I am running on a shitty little ThinkPad laptop with spotty internet and cell service so my performance will be abysmal, but let's try something.
Update: nevermind, it's way too slow (5-10 minutes per response, simple-moderate complexity of questions/requests). I'll update this when I get back to my main computer at with home a powerful GPU and better internet connection.